- January 28, 2020
- Wim Temmerman, Vice President Sales EMEA

You have a nicely laid out document, complete with images, color, fonts and information, of course. Not surprisingly, after you scan it, the file size can get pretty large, making it harder to upload or email.
There are two ways to optimize scanned documents using a PDF Editor such as Foxit PhantomPDF. One is text recognition. The other is compression.
To process your document and turn it into a PDF, you can simply drop it into Foxit PhantomPDF. If you try to select any of the text, however, you’ll see that nothing happens because your document is merely a snapshot of the page. It doesn’t contain any text information.
Although PhantomPDF has already converted your file to a PDF file, to supply the missing text information, go to File > Optimize Scan. Here, you’ll get a number of options.
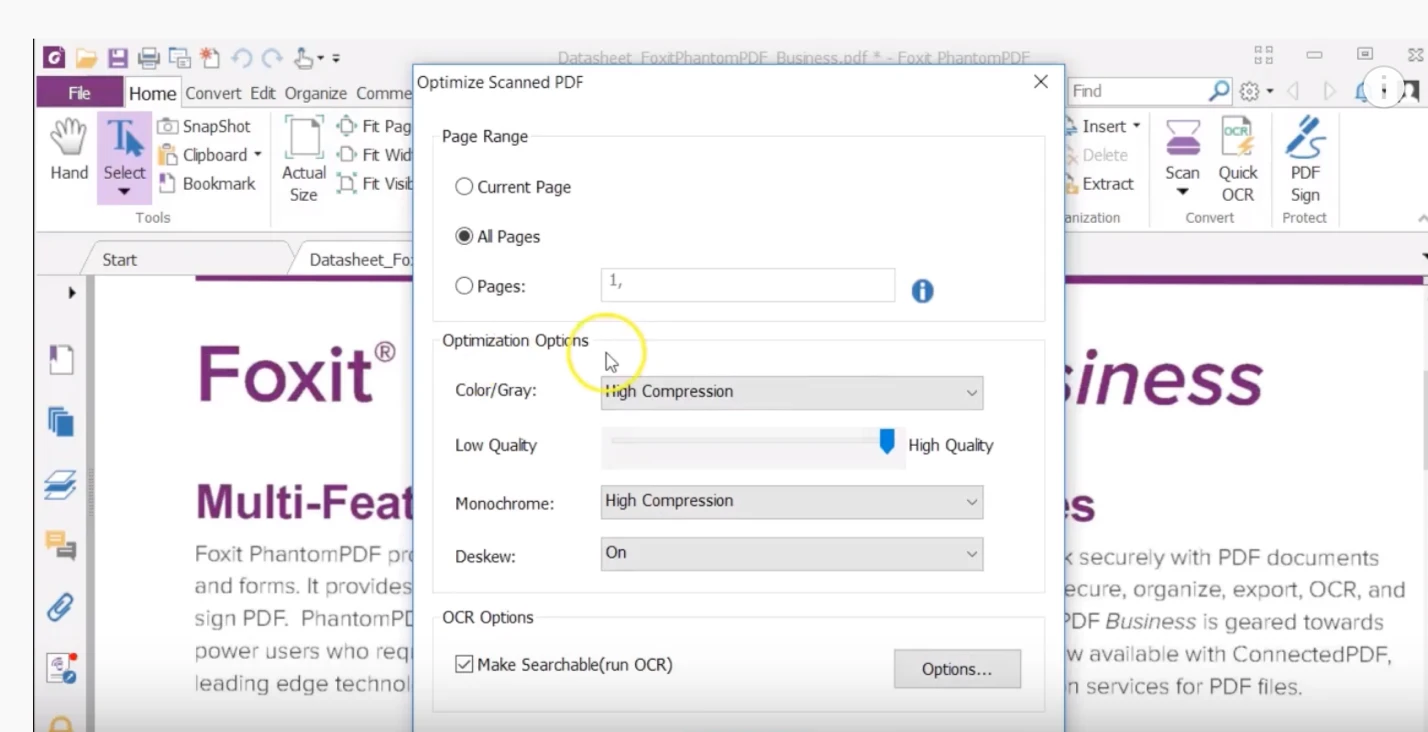
First, you can select a range of pages to process.
Then you have several options for optimization for compression. You have options for color and gray scale images and options for monochrome images, aka, black and white scans.
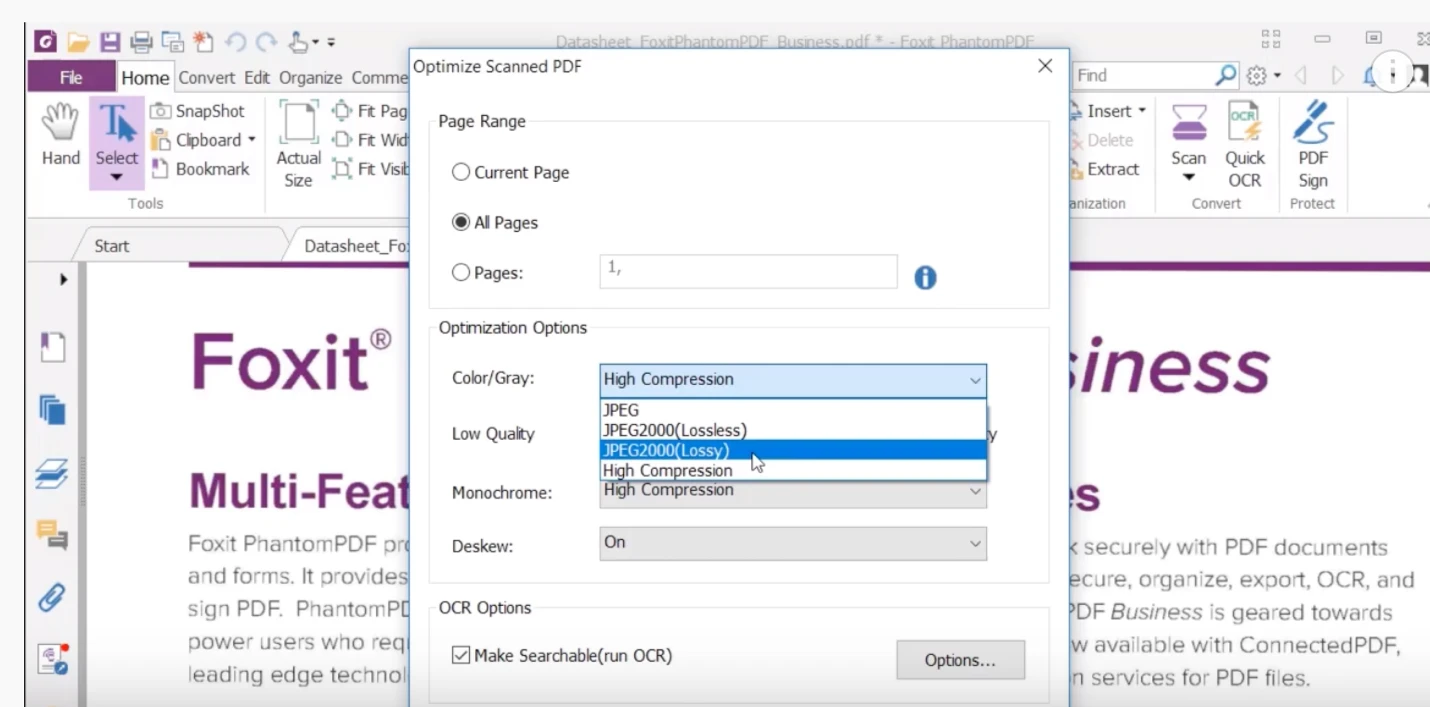
If it’s a colored document, you’ll want that option. You’ll see there are several codecs available. One is the traditional JPEG. Then you have the more recent JPEG 2000 algorithm, which is available both in a lossy and lossless fashion. Lossless means identical pixel by pixel replacement, while lossy means that, as with traditional JPEG, some alterations may occur in an image, but in a way that the average viewer shouldn’t really notice them.
You have a quality slider and a set of options for compression again. The high compression option will try to separate the page content into several layers, which are then compressed individually, preserving the legibility of the text in the document for OCR (Optical Character Recognition, aka, text recognition). You also have a set of options for language. And you can select whether to create searchable text or editable text.
Once you’ve made your choices, click OK to begin processing. The document will be OCR’d, as we like to say, and compressed. If you zoom into the result, you’ll find that the text is quite legible. You can also select text now because text information for the PDF document has been generated and embedded in the PDF.
Now it’s time to save the document. One the best things about this type of compression is that you can end up with as little as few hundred kilobytes instead of megabytes. So you have a reduction in size of about 1:20 which is a considerable factor for sharing and storage.
Hi:
All my color scans produce a light gray background, even though the original’s background was was pure white (a printed text document). This is a serious deficiency in Foxit PDF Editor.
This article does not address this common and serious issue.
I’m using a Canon TR4600, which has no settings for avoiding this either.
Also, please point me to an article that shows how to remove or avoid a grey background in color scans.
Thank you.
Peter Lairo
[email protected]