- June 26, 2018
- Thomas Zellmann, Product Evangelist
Today, many people still scan their documents to image files such as TIFF, JPEGs, PNG and/or BMP. If you do the same, that means you’re creating a picture of your document that has nothing more to offer other than a visual representation. It’s not searchable. It’s not accessible. And it’s got a lot of disadvantages.
Sometimes scanning this way results in different image files, giving you a zoo of multiple formats for your scanned documents, which is a big disadvantage.
Another disadvantage is lack of metadata. Yes, there are options for putting some proprietary metadata into TIFF files, but not in JPEG. That’s why people end up having both JPEG and TIFF files in a multipage format for scanned documents.
Last but not the least disadvantage is that these “documents” are zero percent accessible. All in all, this is an unacceptable outcome. What is acceptable is PDF. Here’s why.
PDF is based on ISO 32000, the big standard that has everything included
According to the International Organization for Standardization, ISO 32000 “specifies a digital form for representing electronic documents to enable users to exchange and view electronic documents independent of the environment in which they were created or the environment in which they are viewed or printed.”
PDF can provide lossless compression
For black and white documents, PDF can provide lossless compression that gives you no difference in what you see onscreen or the number of pixels. Compare it to your scanned page and you can see the quality. You don’t see a difference by design.
PDF layers render your documents perfectly
If you’ve scanned your documents to black and white, you can convert them to PDF and make them searchable and make them smaller. Or reduce your overall archive size in color documents. And you can still save several gigabytes or petabytes.
Sometimes, little things can make it difficult to scan documents. Take marketing collateral for example. It typically consists of characters of written text that are sometimes black and white and sometimes in color. And often, there are images like the company logo that has color and text embedded together.
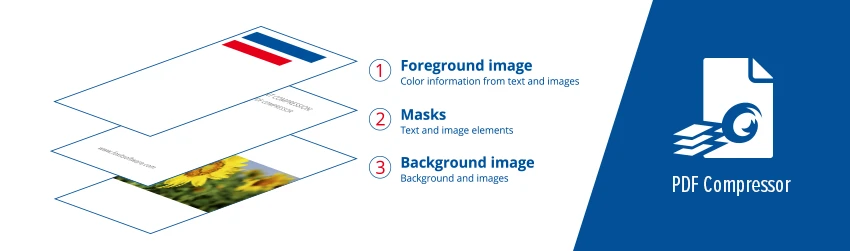
There’s just not a single compression scheme that allows you to make this document small and keep the text in the perfect shape. With PDF, you can use layering to segment this image into sorted content that then can be addressed layer by layer with the best applicable compression schema. It might be JPEG or it might even be the TIFF Group 4. All are available in PDF.

But the layers are sorted in other than the big example where JPEG would fail on the text part or make it really big or the TIFF would fail on the image part. We do a segmentation on those layers and sort it out. The background layer is just an image part of it, which can be compressed with JPEG or JPEG 2000. The middle layer is the black-and-white-text extract. The foreground layer just contains the color of what the text had before. These all get layered on top of each other that are rendered automatically in every PDF reader to represent the documents perfectly. Meanwhile, the layers can be compressed tremendously because they are sorted for specialized compression schema that’s all in PDF.
PDF is easily made accessible
Most governments have laws that require electronic information that’s developed or purchased to be accessible by vision- and hearing-impaired people. Many businesses and private organizations have adopted these policies too.
How do you ensure you’re creating an accessible PDF? Follow these best practices.
So, there’s no need to scan black and white again. You can scan to PDF while retaining full color information. It’s perfect quality and even smaller than the TIFF representation of the same document. And it’s easy to ensure your PDF files are accessible.