
Foxit® PDF IFilter - Visão Geral
Procure documentos PDF com o IFilter para PDF mais rápido do mercado
O Foxit PDF IFilter fornece uma indexação extremamente rápida, permitindo que os usuários indexem uma grande quantidade de documentos PDF e, em seguida, localizem rapidamente os documentos desejados especificando critérios de pesquisa. Desenvolvido com base na interface de indexação de IFilter da Microsoft®, o Foxit PDF IFilter extrai dados de documentos PDF e retorna os resultados do índice para softwares de mecanismo de pesquisa. Ele vai muito além dos produtos da Adobe®, indexando o conteúdo do PDF, além de títulos, assuntos, autores, palavras-chave, portfólios PDF, anotações, textos e dados de formulários (formulários XFA e PDF padrão), marcadores, anexos, data/hora de criação, número de páginas e nomes dos aplicativos de criação. Isso resulta em resultados de pesquisa mais precisos. Os documentos PDF podem ser pesquisados rapidamente no desktop, em um servidor corporativo ou na Web com o uso de palavras-chave. Esses documentos PDF podem ser arquivos, anexos de e-mail ou registros de banco de dados.
O suporte exclusivo para vários núcleos proporciona a capacidade de pesquisa mais rápida disponível no mercado
O Foxit PDF IFilter foi projetado para desencadear o poder de computação das atuais arquiteturas avançadas de servidor de realizar rastreamentos em altíssimas velocidades. Ao contrário de outros produtos de IFilter, ele tira proveito máximo das atuais arquiteturas de servidor com vários núcleos, é seguro para threads e está disponível para sistemas operacionais de 32 bits e 64 bits, o que o torna definitivamente o IFilter para PDF mais rápido do mercado.
Reduz o custo total de propriedade dos clientes
Os níveis superiores de desempenho e escalabilidade do Foxit PDF IFilter diminuem o custo total de propriedade dos clientes por meio de reduções nos custos de hardware de servidor, área ocupada do data center, energia, resfriamento e administração.
Compatível com o seu ambiente existente
O Foxit PDF IFilter oferece suporte para vários idiomas, incluindo idiomas asiáticos e idiomas da direita para a esquerda, com facilidade. O Foxit PDF IFilter oferece suporte para a indexação de arquivos ISO 32000-1 (que se baseiam em PDF 1.7), PDF-A e Adobe PDF.
Avaliação gratuita Download
Teste o Foxit PDF IFilter com uma Avaliação gratuita Download e descubra como é possível procurar documentos PDF com rapidez e facilidade usando o melhor produto de IFilter para PDF da indústria.
* Acesso baseado em licença, não propriedade
Plug-in para mecanismos de pesquisa baseados na interface de indexação IFilter da Microsoft
O Foxit PDF IFilter é uma implementação robusta da interface de indexação IFilter da Microsoft®. Ele funciona com todos os produtos de pesquisa e recuperação que dão suporte para a interface IFilter (por exemplo, o SharePoint® e o SQL Server®). Esses produtos usam programas de filtragem específicos para cada formato (chamados de IFilters) para determinados tipos de arquivo (por exemplo, HTML). O Foxit PDF IFilter é um desses programas e está voltado para documentos PDF. A interface de usuário para pesquisar documentos pode ser o Windows Explorer, um navegador de internet, um banco de dados front-end, um script de consulta ou um aplicativo personalizado.
O Foxit PDF IFilter atua como um plug-in para mecanismos de pesquisa de texto completo. Geralmente, um mecanismo de pesquisa funciona em duas etapas:
- O mecanismo de pesquisa percorre um local designado (como uma pasta de arquivos ou um banco de dados), indexa todos os documentos ou os documentos recentemente modificados (incluindo documentos PDF) e depois armazena os resultados da indexação em um banco de dados interno.
- Os usuários especificam as palavras-chave que eles desejam pesquisar, e o mecanismo de pesquisa as procura nos resultados da indexação do banco de dados interno, respondendo aos usuários com todos os documentos que contêm as palavras-chave especificadas.
Durante a etapa 1, o mecanismo de pesquisa não compreende o formato de um documento PDF. Portanto, ele pesquisa o Registro do Windows em busca de um IFilter apropriado para PDF e encontra o Foxit PDF IFilter. Como o Foxit PDF IFilter compreende o formato PDF, ele remove a formatação incorporada, extrai o texto dos documentos e, em seguida, retorna esse texto ao mecanismo de pesquisa.
O Foxit PDF IFilter funciona nos seguintes ambientes de mecanismo de pesquisa:
- Microsoft SharePoint Server: SharePoint Server 2007, SharePoint Server 2010, SharePoint Server 2013
- Microsoft Exchange Server: Exchange Server 2007, Exchange Server 2010
- Microsoft SQL Server: SQL Server 2008, SQL Server 2010, SQL Server 2014, SQL Server 2016, SQL Server 2017, SQL Server 2019
Como alternativa a pesquisas interativas, consultas também podem ser enviadas programaticamente sem nenhuma interface de usuário nos seguintes sistemas operacionais Windows:
- Windows 10
- Windows 8
- Windows 7
- Windows Vista
- Windows Server 2012
- Windows Server 2008
- Windows Server 2003
Recurso de índice otimizado
- A indexação extremamente rápida permite que os usuários pesquisem mais documentos em menos tempo. O gerenciamento de memória exclusivo dá suporte para multithreading e tira proveito máximo de servidores com vários núcleos/CPUs.
Suporte para a indexação de arquivos PDF ISO 32000, (PDF 1.7), PDF-A, portfólios PDF e arquivos Adobe® PDF.
- Suporte para os documentos PDF que você possui atualmente.
Indexação de documentos PDF
- Localize documentos PDF indexando o conteúdo dos PDFs.
Indexação de formulários PDF
- Localize formulários PDF e XFA padrão indexando o texto e os dados de formulários PDF.
Indexação de atributos de PDF
- Localize documentos PDF indexando títulos, autores, assuntos e palavras-chave de PDFs, entre vários outros atributos.
Indexação de anotações, marcadores e anexos PDF
- Localize documentos PDF indexando informações de anotações, marcadores e anexos.
Definições de configuração e suporte para registro em log
- Melhore a experiência do usuário e notifique os desenvolvedores se ocorrer um erro.
Uma versão de 64 bits
- Maior desempenho - tira proveito das principais arquiteturas de servidor.
Suporte para vários idiomas - incluindo idiomas da direita para a esquerda
- Suporte para a sua base mundial de usuários.
Compatível com o Microsoft SharePoint Server, o Microsoft Exchange Server, o SQL Server, o Windows Indexing Server
- Compatível com o seu ambiente existente.
Foxit PDF IFilter - Server Test, with SharePoint 2010
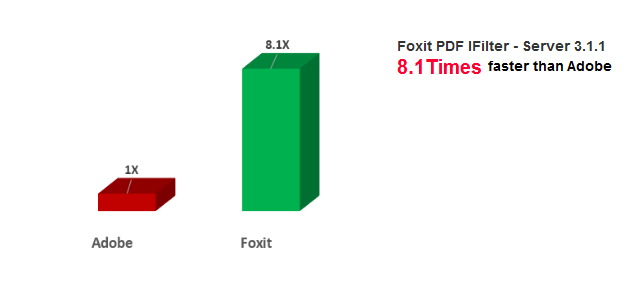
Os principais resultados do teste incluem:
- Tempo de rastreamento de conjuntos de dados
- O Foxit PDF IFilter - Server 3.1.1 finalizou o rastreamento completo em apenas 32 minutos
- 8,1x mais rápido que o Adobe PDF IFilter
- O Foxit PDF IFilter - Server 3.1.1 finalizou o rastreamento completo em apenas 32 minutos
- Média de arquivos por segundo
- 5,54 arquivos por segundo no SharePoint 2010 (64 bits)
- 8,15x melhor que o Adobe PDF IFilter
Observação: Como o Foxit PDF IFilter oferece suporte para mais recursos, ele precisa de mais tempo para concluir a recuperação.
- Comparação de recursos
| Recurso Produto | Foxit PDF IFilter 3.1.1 | PDFlib TET PDF IFilter 5.0 | Adobe IFilter 11.0 | |
| Extrair texto de PDF | √ | √ | √ | |
| Extrair atributos de PDF | √ | √ | √ | |
| Extrair marcadores de PDF | √ | X | X | |
| Extrair anotações de PDF | √ | X | Somente texto explicativo e máquina de escrever | |
| Extrair anexos de PDF | √ | √ | √ | |
| Extrair formulário | Dica de ferramenta | √ | X | X |
| Nome | √ | X | X | |
| Rótulo | √ | X | X | |
| Lista de itens | √ | X | Todos os itens na lista de itens de Caixa de Listagem e parte dos itens na lista de itens de Caixa de Combinação | |
| Valor Padrão | √ | X | Somente campo de texto | |
| Extrair formulário XFA/XML | XFA dinâmico | √ | X | X |
| XFA estático | √ | √ | √ | |
| Extrair portfólio PDF | Atributos de portfólio | √ | √ | X |
| Conteúdo PDF | √ | √ | X | |
| Marcador | √ | X | X | |
| Anotação | √ | X | X | |
| Extrair texto da direita para a esquerda | √ | √ | √ | |
O Foxit PDF IFilter é fornecido em versões de 32 bits e 64 bits do Windows®. Selecione a versão que corresponde aos seus requisitos de sistema.
Amostra de instalação - Microsoft® Office® SharePoint Server®
Para instalar o Foxit PDF IFilter com o Microsoft Office SharePoint Server, siga estas etapas simples:
Observe que o Microsoft Office SharePoint Server foi instalado com sucesso.
- Baixe o Foxit PDF IFilter no site da Foxit Corporation e salve-o no computador onde você deseja instalá-lo.
- Pare o serviço de administração do IIS: Iniciar > Configurações > Painel de Controle > Ferramentas do Administrador > Serviços > Serviço de Administração do IIS > Parar. Feche a janela.
- Execute o programa de instalação do Foxit PDF IFilter para instalar o IFilter no servidor.
- Baixe o ícone de PDF no endereço /resource/images/icons/pdficon.gif
- Copie o arquivo .GIF baixado em "Unidade:\Arquivos de Programas\Arquivos Comuns\Microsoft Shared\Web Server Extensions\14\Template\Images".
- Edite o arquivo "Unidade:\Arquivos de Programas\Arquivos Comuns\Microsoft Shared\Web server extensions\14\Template\Xml\DOCICON.XML"
- Clique com o botão direito do mouse no arquivo DOCICON.XML, clique em Abrir com e depois selecione Bloco de Notas.
- Adicione uma entrada para a extensão .pdf. Por exemplo, em que ICPDF é o nome do arquivo .gif:
<Mapping Key="pdf" Value="pdficon.gif"/> - No menu Arquivo, clique em Salvar e depois saia do Bloco de Notas.

- Execute um comando iisreset:
- Clique em Iniciar > Executar > digite "cmd" na linha Abrir > clique em OK > digite "iisreset" no prompt de comando > pressione Enter.
- Feche a janela.
- Clique em Iniciar > Executar > digite "cmd" na linha Abrir > clique em OK > digite "iisreset" no prompt de comando > pressione Enter.
- Pare e inicie o Serviço de Pesquisa do SharePoint executando os seguintes comandos:
- net stop spsearch4
- net start spsearch4
- net stop osearch14
- net start osearch14
{kind=link}
Agora, o Microsoft Office SharePoint Server pode indexar arquivos PDF.
Nota:
Para obter instruções de instalação detalhadas com outros mecanismos de pesquisa, consulte seus respectivos manuais do usuário (https://www.foxit.com/pt-br/support/usermanuals/)
Observações adicionais:
O Foxit PDF IFilter não tem uma interface de usuário. Como o Foxit PDF IFilter atua como um plug-in para vários mecanismos de pesquisa, o mecanismo de pesquisa é o responsável por interpretar o texto retornado e, em seguida, apresentar as informações para o usuário.
O pacote de instalação irá descompactar um arquivo de idioma denominado fpdfcjk.bin na pasta de instalação. Esse arquivo irá ajudá-lo a indexar documentos PDF contendo caracteres nos idiomas chinês/japonês/coreano.
Para clientes existentes do Foxit PDF IFilter 2.X que desejam atualizar, os novos recursos do PDF IFilter 3.X incluem:
- Indexação de texto e dados de formulários a partir de formulários PDF e XFA padrão.
- Indexação de portfólios PDF.
- Indexação de documentos PDF em idiomas da direita para a esquerda.
| Price( US$ ) | |
|---|---|
| PDF IFilter - Produção | $1,999.00 por servidor |
| PDF IFilter - Teste/desenvolvimento/failover | $999.50 por servidor |
| Atualização do PDF IFilter 1.X para o PDF IFilter 3.X (Servidor de Produção) | $1,399.30 por servidor |
| Atualização do PDF IFilter 2.X para o PDF IFilter 3.X (Servidor de Produção) | $999.50 por servidor |
| Atualização do PDF IFilter 1.X para o PDF IFilter 3.X (Teste/desenvolvimento/failover) | $699.65 por servidor |
| Atualização do PDF IFilter 2.X para o PDF IFilter 3.X (Teste/desenvolvimento/failover) | $499.75 por servidor |